
Prometheus telah menjadi salah satu tools pemantauan (monitoring) yang paling populer dalam dunia DevOps dan cloud-native ecosystem.
Salah satu kekuatan utama Prometheus terletak pada sistem metric yang fleksibel dan powerful.
Dalam artikel ini, kita akan menjelajahi berbagai metric types prometheus yang tersedia dan bagaimana masing-masing tipe digunakan dalam pemantauan sistem.
Apa Itu Percentil dan Quantile?
Percentil
Percentil nilai di bawah persentase tertentu dari data dalam sebuah dataset. Misalnya, percentil ke-95 (P95) adalah nilai di mana 95% data berada di bawah nilai tersebut dan 5% berada di atasnya.
Percentil merupakan representasi persentase antara 0 dan 100. Contohnya,”95 percentil dari sebuah distribusi latency adalah 120ms”. Artinya 95% dari distribusi latency lebih cepat dari 120ms dan 5% lebih lambat dari 120ms.
Quantile
Quantile konsep yang lebih umum yang membagi dataset menjadi interval probabilitas yang sama. Percentil adalah kasus khusus dari quantile di mana pembagian dilakukan per 1%. Quantile ke-0.95 sama dengan percentil ke-95.
Sedangkan quantile merupakan representasi nilai antara 0 dan 1. Contohnya, 0.95 quantile dari sebuah distribusi latency sama dengan 95 percentil
4 Jenis Metric Types Prometheus
1. Counter
Counter adalah metric type paling dasar yang nilainya hanya meningkat (monotonically increasing).
Counter biasanya digunakan untuk menghitung jumlah kejadian seperti jumlah request HTTP, jumlah error, atau jumlah task yang selesai.
Karakteristik Counter
- Nilai hanya bertambah (tidak pernah berkurang)
- Direset ke nol saat proses restart komputer
- Ideal untuk menghitung rate (laju) perubahan
Contoh Penggunan
# TYPE node_network_receive_bytes_total counter

Kita juga bisa melihat di sistem operasi linux.
cat /proc/net/dev

Pengujian Metric Types Counter dengan Speedtest CLI
Pastikan sudah install speedtest cli pada sistem operasi linux yang digunakan, jalankan perintah dibawah sebanyak dua kali.
speedtest

Jalankan perintah irate(node_network_receive_bytes_total{instance=”localhost:9100″}[1m]) untuk melihat graph pada prometheus atau bisa menggunakan function rate()

2. Gauge
Gauge adalah metrik yang nilainya bisa naik dan turun, mewakili nilai yang berfluktuasi seiring waktu.
Karakteristik Gauge
- Nilai dapat meningkat atau menurun
- Mewakili snapshot nilai pada titik waktu tertentu
- Tidak ada batasan nilai
Contoh penggunaan
- Penggunaan memori (memory usage)
- Jumlah koneksi aktif
- Suhu CPU
- Panjang antrian (queue length)
# TYPE node_memory_MemFree_bytes gauge



Bisa juga menjalankan perintah linux cat /proc/meminfo
3. Histogram
Histogram mengukur distribusi nilai dalam buckets yang telah ditentukan sebelumnya. Tipe ini sangat berguna untuk menganalisis latency, ukuran response, atau distribusi nilai numerik lainnya.
Histogram akan mengelompokan value dalam sebuah bucket (le = less than or equal/ kurang dari sama dengan) secara kumulatif.

Karakteristik Histogram
- Membagi data ke dalam buckets yang dapat dikonfigurasi
- Menghitung count dan sum dari nilai
- Menyediakan data untuk menghitung percentil
Histogram menghasilkan beberapa time series
- _bucket: counter untuk setiap bucket
- _sum: jumlah semua nilai
- _count: jumlah total observasi
Salah satu metric histogram yang dapat kita gunakan prometheus_http_request_duration_seconds_bucket

Untuk menghitung quantile/ percentil metric histogram kita dapat menggunakan histogram_quantile()
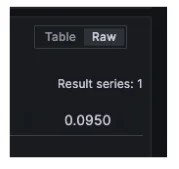
Contoh query mencari quantile histogram: histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket{handler=”/metrics”}[10m])) by (le))

Hasilnya yang kita dapatkan nantinya berupa single value. Misalnya kita mendapatkan hasilnya adalah 0.0950, artinya 95% request di /metrics dalam 10 menit terakhir selesai diproses dalam 0.095 detik atau lebih cepat dari itu.
4. Summary
Metric summary sebenarnya sama seperti metric histogram. Perbedaanya adalah, data yang dikeluarkan oleh histogram merupakan raw data yang belum berbentuk, sedangkan summary sudah berberntuk quantile.
Artinya, quantile di histogram di kalkulasikan oleh segi server prometheus, sedangkan quantile summary dikalkulasikan oleh segi client (system yang di scrape metricnya: Linux, Database, App, dll)
Jadi kita tinggal melakukan query instant vector biasa sudah cukup untuk mendapatkan data quantile.

go_gc_duration_seconds{instance=”localhost:9100″, quantile=”0.75″}

Karakteristik Summary
- Menghitung percentil di sisi client (application side)
- Lebih akurat untuk percentil tetapi kurang fleksibel
- Tidak memerlukan bucket configuration
Memahami berbagai metric types prometheus adalah fundamental untuk membangun sistem monitoring yang efektif.
Counter untuk menghitung kejadian, Gauge untuk nilai yang berfluktuasi, Histogram untuk distribusi dengan fleksibilitas query, dan Summary untuk percentil yang akurat.
Pemilihan metric types yang tepat akan menentukan seberapa baik kamu dapat menganalisis dan memecahkan masalah dalam sistem.
Dengan penguasaan terhadap keempat metric types ini, kamu dapat merancang sistem monitoring yang memberikan visibilitas komprehensif terhadap performa dan kesehatan aplikasi, memungkinkan deteksi dini masalah dan pengambilan keputusan yang berdasarkan data.